Testing Complex Rule Induction with Text Games
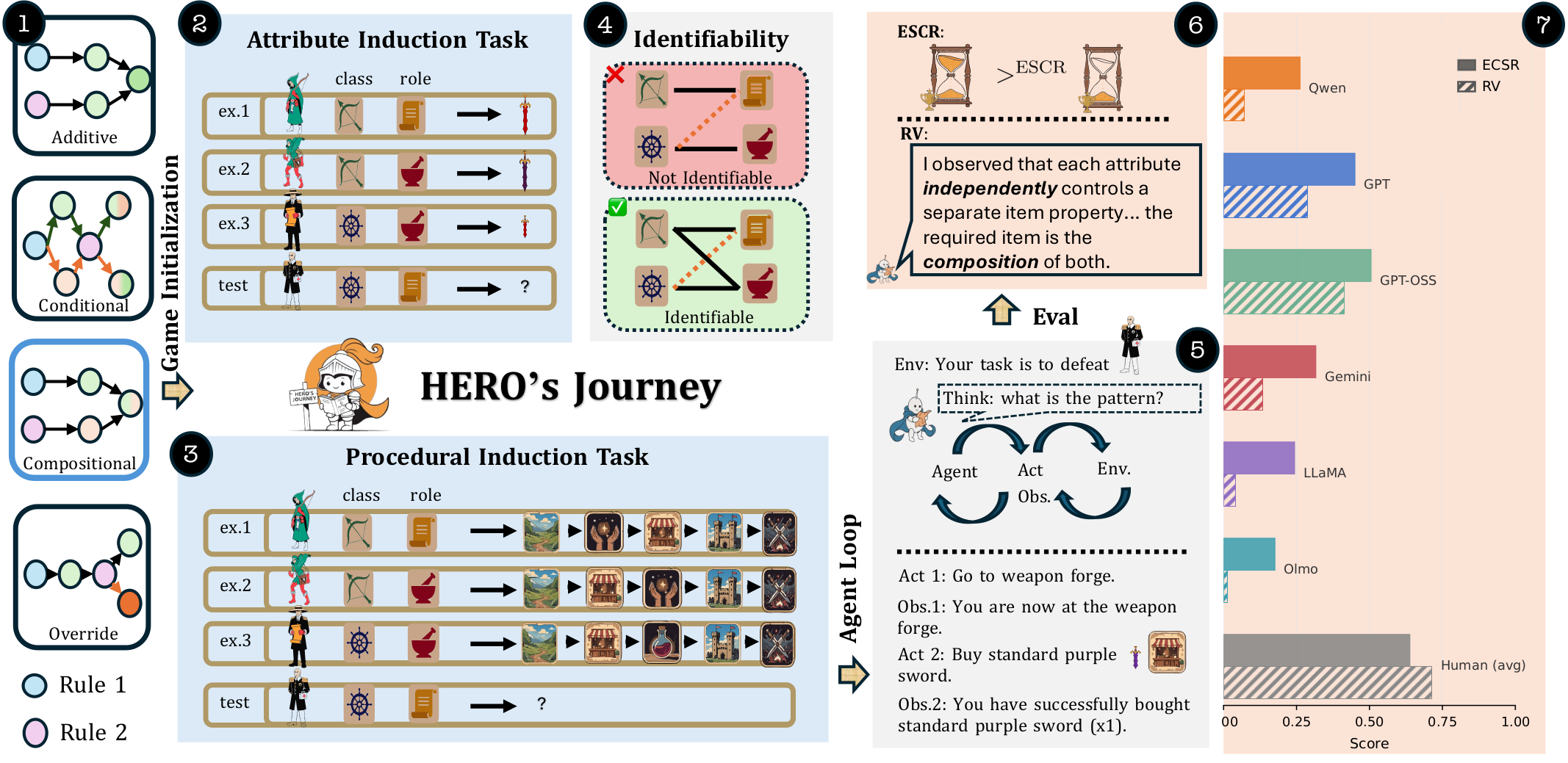
We introduce Hero's Journey, a benchmark for rule induction in goal-directed episodic tasks, where an agent must infer hidden rules from demonstrations and act on them through multi-step execution. Across eight tasks in two families, each with four structural rule forms, controllable lexical grounding, and identifiability conditions, the agent must:
We evaluate models along two dimensions:
We present our results in an interactive leaderboard. Use the Task Explorer to walk through real demonstration episodes and try a held-out entity yourself, or the Leaderboard to compare models across all eight tasks.
Please cite our paper if you found our work to be useful in your work:
@misc{zheng2026herosjourneytestingcomplex,
title={HERO'S JOURNEY: Testing Complex Rule Induction with Text Games},
author={Anshun Asher Zheng and Kanishka Misra and David I. Beaver and Junyi Jessy Li},
year={2026},
eprint={2606.02556},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2606.02556},
}
The agent must infer a hidden requirement from demonstration episodes, then apply it to a held-out entity. Pick a task, step through the demos, then try the held-out episode yourself before revealing the answer. Some demos are distractors with no pattern: hit Reveal pattern to see which, and the rule. Toggle semantic ⇄ nonce names to feel why world knowledge sometimes helps, and sometimes can't.
Efficiency-calibrated success rate (ECSR) and rule-verbalization score (RV, 0–1) per model and task. Toggle models with the chips, switch the metric, and click a table header to sort.